DATA MANAGEMENT CHALLENGES IN PRODUCTION MACHINE LEARNING
INTRODUCTION
Machine learning’s importance in modern computing cannot be overstated. Machine learning is becoming increasingly popular as a method for extracting knowledge from data and tackling a wide range of computationally difficult tasks, including machine perception, language understanding, health care, genetics, and even the conservation of endangered species [1]. Machine learning is often used to describe the one-time application of a learning algorithm to a given dataset. The user of machine learning in these instances is usually a data scientist or analyst who wants to try it out or utilises it to extract knowledge from data. Our focus here is different, and it considers machine learning implementation in production. This entails creating a pipeline that reliably ingests training datasets as input and produces a model as output, in most cases constantly and gracefully dealing with various forms of failures. This scenario usually involves a group of engineers that spend a substantial amount of their time to the less glamorous parts of machine learning, such as maintaining and monitoring machine learning pipelines [2].
PRODUCTION MACHINE LEARNING: OVERVIEW AND ASSUMPTIONS
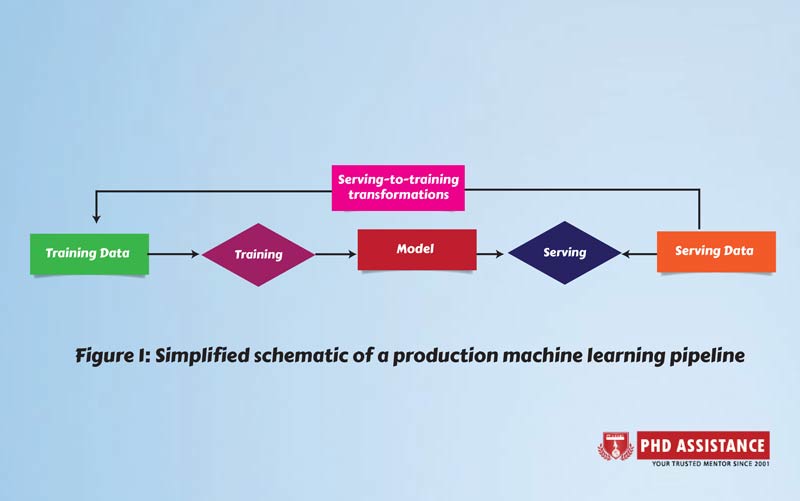
A high-level representation of a production machine learning pipeline is shown in Figure 1. The training datasets that will be provided to the machine learning algorithm are the system’s input. The result is a machine-learned model, which is picked up by serving infrastructure and combined with serving data to provide predictions. Typically, a subset of the serving data is transformed and sent back into the system as new training data, along with the model’s predictions.
The training dataset can be represented as a (big) collection of flat records, each with a large number of scalar-valued features. This approach is widely used in practise, and numerous existing machine learning frameworks use it as well. a semi-continuous arrangement in which training data is sent in batches, the machine learning algorithm is run on a sliding window of recent batches, and a new batch of data prompts the construction of a new model. Many of the issues we’ll discuss below are also applicable in a pure streaming system, as well as for one-time data processing on a single batch. PhD Assistance experts has experience in handling dissertation and assignment in computer science research with assured 2:1 distinction. Talk to Experts Now
DATA ISSUES IN PRODUCTION MACHINE LEARNING
The primary issues in handling data for production machine learning pipelines are discussed in this section.
Understanding
Engineers who are first setting up a machine learning pipeline spend a large amount of time evaluating their raw data. This procedure entails creating and visualising key aspects of the data, as well as recognising any anomalies or outliers. It can be difficult to scale this technique to enormous amounts of training data. Techniques established for online analytical processing [3], data-driven visualisation recommendation [4], and approximation query processing [5] can all be used to create tools that help people comprehend their own data. Another important step for engineers is to figure out how to encode their data into features that the trainer can understand. For example, if a string feature in the raw data contains nation identifiers; one hot encoding can be used to transform it to an integer feature. A fascinating and relatively unexplored research field is automatically recommending and producing transformations from raw data to features based on data qualities. When it comes to comprehending facts, context is equally crucial. In order to design a maintainable machine learning pipeline, it is critical to clearly identify explicit and implicit data dependencies, as described in [2]. Many of the tools developed for data-provenance management may be used to track some of these dependencies, allowing us to better understand how data travels through these complicated pipelines.
Validation
It is difficult to overlook the fact that data validity has a significant impact on the quality of the model developed. Validity entails ensuring that training data contains the expected characteristics that these features have the expected values that features are associated as expected, and that serving data does not diverge from training data.
Some of the issues can be solved by using well-known database system technologies. The predicted properties and the characteristics of their values, for example, can be encoded using something close to a training data format. Hire PhD Assistance experts to develop your algorithm and coding implementation for your Computer Science dissertation Services.
Furthermore, machine learning introduces new restrictions that must be verified, such as bounds on the drift in the statistical distribution of feature values in the training data, or the usage of an embedding for some input feature if and only if other features are normalised in a specified way. Furthermore, unlike a traditional DBMS, any schema over training data must be flexible enough to allow changes in training data features as they reflect real-world occurrences.
In production machine learning pipelines, the difference between serving and training data is a primary source of issues. The underlying problem is that the data used to build the model differs from the data used to test it, which almost always means that the predictions provided are inaccurate.
The final stage is to clean the data in order to correct the problem. Cleaning can be accomplished by addressing the source of the problem. Patching the data within the machine learning pipeline as a temporary workaround until the fundamental problem is properly fixed is another option. This method is based on a large body of research on database repair for specific sorts of constraints [4]. A recent study [6] looked at how similar strategies could be used to a specific class of machine learning algorithms.
ENRICHMENT
Enrichment is the addition of new features to the training and serving data in order to increase the quality of the created model. Joining in a new data source to augment current features with new signals is a common form of enrichment.
Discovering which extra signals or changes can meaningfully enrich the data is a major difficulty in this situation. A catalogue of sources and signals can serve as a starting point for discovery, and recent research has looked into the difficulty of data cataloguing in many contexts [7] as well as the finding of links between sources and signals. Another significant issue is assisting the team in comprehending the increase in model quality achieved by adding a specific collection of characteristics to the data. This data will aid the team in determining whether or not to devote resources to applying the enrichment in production. This topic was investigated in a recent study [3] for the situation of joining with new data sources and a certain class of methods, and it would be interesting to consider extensions to additional cases.
Another wrinkle is that data sources may contain sensitive\information and consequently may not be accessible unless the team goes through an access review. Going through a review and gaining access to sensitive data, on the other hand, can result in operating costs. As a result, it’s worth considering whether the enrichment effect can be approximated in a privacy-preserving manner without access to sensitive data, in order to assist the team in deciding whether to apply for access. One option is to use techniques from privacy-preserving learning [7], while past research has focused on learning a privacy-preserving model rather than simulating the influence of new characteristics on model quality.
| Technqiues | Working principle | Advantages | Disadvantage | Application ML with IoT |
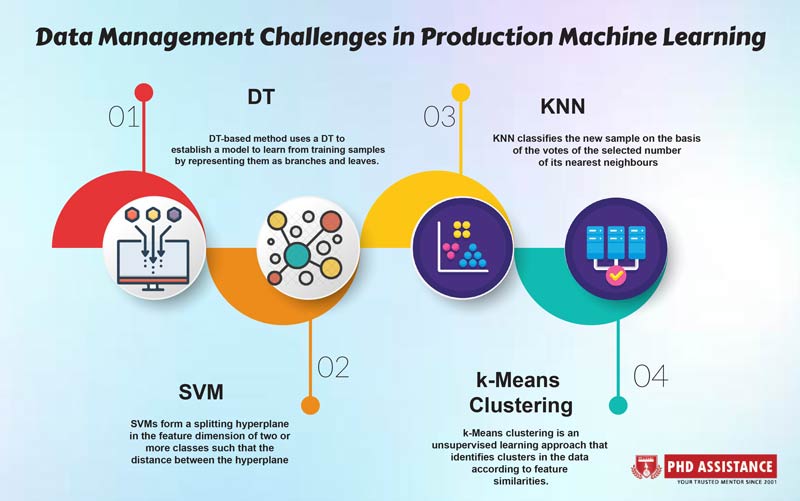
| DT | DT-based method uses a DT to establish a model
to learn from training samples by representing them as branches and leaves. The pretrained model is then used to predict the class of the new sample. |
DT is a simple, easy-to-use and
transparent method. |
DT requires large storage because of its construction
nature. Understanding DTbased methods is easy only if few DTs are involved. |
Detection of intrusion
and suspicious traffic sources |
| SVM | SVMs form a splitting hyperplane
in the feature dimension of two or more classes such that the distance between the hyperplane and the most adjacent sample points of each class is maximised
|
SVMs are known for their
generalisation capability and suitability for data consisting of a large number of feature attributes but a small number of sample points |
The optimal selection of a
kernel is difficult. Understanding and interpreting SVM-based models are difficult. |
Detection of intrusion, malware
and attacks in smart grids |
| KNN | KNN classifies the new sample on the basis of the votes of the selected number of its nearest neighbours; i.e. KNN decides the class of unknown samples by the
majority vote of its nearest neighbours. |
KNN is a popular and effective
ML method for intrusion detection. |
The optimal k value usually
varies from one dataset to another; therefore, determining the optimal value of k may be a challenging and timeconsuming process. |
Detection of intrusions and anomalies
|
| k-Means
clustering |
k-Means clustering is an
unsupervised learning approach that identifies clusters in the data according to feature similarities. K refers to the number of clusters to be generated by the algorithm. |
Unsupervised algorithms are
generally a good choice when generating the labelled data is difficult. k-Means clustering can be used for private data anonymisation in an IoT system. |
k-Means clustering is less effective than supervised
learning methods, specifically in detecting known attacks
|
Sybil detection in
industrial WSNs and private data anonymisation in an IoT system |
Future scope
IT architectures will need to change to accommodate it, but almost every department within a company will undergo adjustments to allow big data to inform and reveal. Data analysis will change, becoming part of a business process instead of a distinct function performed only by trained specialists. Big data productivity will come as a result of giving users across the organization the power to work with diverse data sets through self-services tools. Achieving the vast potential of big data demands a thoughtful, holistic approach to data management, analysis and information intelligence. Across industries, organizations that get ahead of big data will create new operational efficiencies, new revenue streams, differentiated competitive advantage and entirely new business models. Business leaders should start thinking strategically about how to prepare the organizations for big data.
References
- Abousleiman, G. Qu, and O. A. Rawashdeh. North atlantic right whale contact call detection. CoRR, abs/1304.7851, 2013.
- Sculley, G. Holt, D. Golovin, E. Davydov, T. Phillips, D. Ebner, V. Chaudhary, and M. Young. Machine learning: The high interest credit card of technical debt. In SE4ML: Software Engineering for Machine Learning (NIPS 2014 Workshop), 2014.
- Kumar, J. F. Naughton, J. M. Patel, and X. Zhu. To join or not to join?: Thinking twice about joins before feature selection. In Proceedings of the 2016 International Conference on Management of Data, SIGMOD Conference 2016, San Francisco, CA, USA, June 26 – July 01, 2016, pages 19–34, 2016.
- Vartak, S. Rahman, S. Madden, A. G. Parameswaran, and N. Polyzotis. SEEDB: efficient data-driven visualization recommendations to support visual analytics. PVLDB, 8(13):2182–2193, 2015.
- Halevy, F. Korn, N. F. Noy, C. Olston, N. Polyzotis, S. Roy, and S. E. Whang. Goods: Organizing google’s datasets. In Proceedings of the 2016 International Conference on Management of Data, SIGMOD ’16, pages 795–806, New York, NY, USA, 2016. ACM
- Krishnan, J. Wang, E. Wu, M. J. Franklin, and K. Goldberg. Activeclean: Interactive data cleaning for statistical modeling. PVLDB, 9(12):948–959, 2016.
- M. Hellerstein, V. Sreekanti, J. E. Gonzales, Sudhansku, Arora, A. Bhattacharyya, S. Das, A. Dey, M. Donsky, G. Fierro, S. Nag, K. Ramachandran, C. She, E. Sun, C. Steinbach, and V. Subramanian. Establishing common ground with data context. In Proceedings of CIDR 2017, 2017

