Selecting the right type of algorithm for various applications
Machine learning algorithms may be classified mainly into three main types. Supervised learning constructs a mathematical model from the training data, including input and output labels. The techniques of data categorization and regression are deemed supervised learning. In unsupervised learning, the system constructs a model using just the input characteristics but no output labeling. The classifiers are then trained to search the dataset for a specific pattern. Examples of uncontrolled learning algorithms including clustering and segmentation. In reinforcement learning, the model learns to complete a task in reinforcement learning by executing a number of actions and choices that it improves itself and then understands from the information from these actions and decisions (Lee & Shin, 2020).
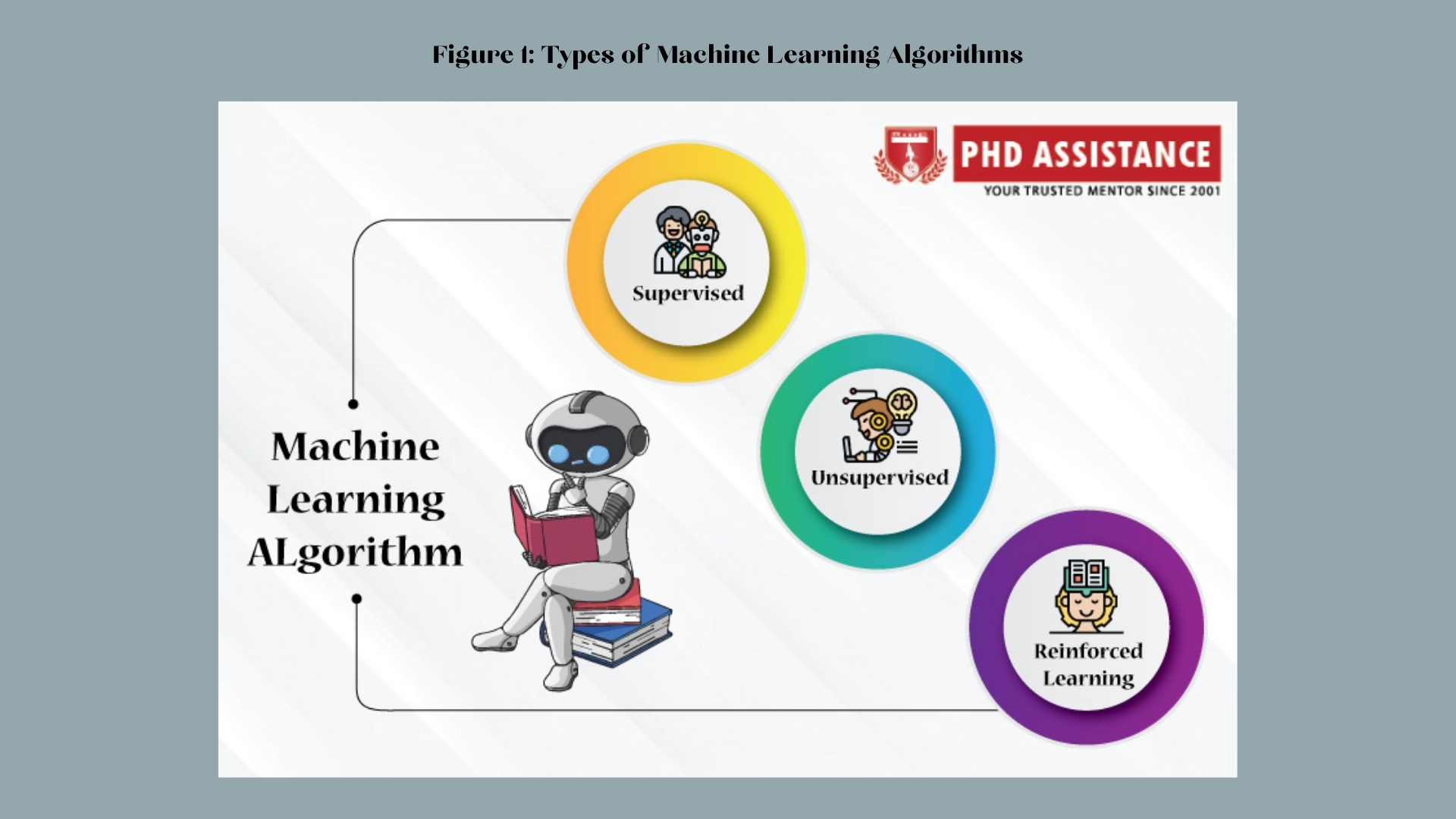
Figure 1: Types of Machine Learning Algorithms
Understanding the Data
The first and primary stage in determining an algorithm is the understanding of your data. One needs to acquaint themselves with data before thinking about the various algorithms. One easy approach of doing this is to view data and attempt to detect patterns in them, to watch their behavior and especially their size. The size of the data is an important parameter. Some algorithms do better than others with greater data (Mahfouz et al., 2020). For instance, algorithms with higher bias or lower variance classification are more effective than lower bias or higher variance classifications in limited training datasets (Richter et al., 2020). For instance, Naïve Bayes will do better than kNN if the training data is smaller.
The feature of data is another parameter. The way the data is created, and whether it is linear to the data must be considered. Then maybe a linear model is most suited, such as regressions or SVM. However, if your data is more complicated then more complicated algorithms like Random forest may be required. The features being linked or sequential also requires specific type of algorithms. The type of data is an important parameter (Vabalas et al., 2019). The data maybe classified into input or output. Use a supervised learning method if the input data are labeled; otherwise, unsupervised algorithm must be used. If the output is numerical, on the other hand, then regression will be used, but if it is a collection of groups, it is an issue of clustering.
Required Accuracy
In the next step, it should be decided whether or not accuracy is important for the issue one is attempting to address. The accuracy of an application refers to the capacity of an individual method to estimate a response from a given observation near to the right response (Garg, 2020). Sometimes a correct reply to our target application is not essential. If the
approximation is strong enough, by adopting an approximate model, we may considerably reduce the training and processing time. Approximation approaches, such as linear regression of non-linear data, prevent or do not execute data overfitting.
Speed
Sometimes users have to choose between speed and accuracy in order to decide on an algorithm. Typically, more precision takes longer to achieve, over a longer timeline, while faster processing has less accuracy. The incredibly simple algorithms like Naïve Bayes and Logistic regression are used often since they’re simple, quick to run algorithms. Using more advanced techniques like support vector machine learning, neural networks, and random forests, might take a lot longer to learn, and would also give higher accuracy. Therefore, the question is how much is the project worth, Is time more important or the accuracy. If it is time, simpler methods must be used, while if accuracy is more important, then one has to go with more sophisticated ones.
Parameters
The parameters will impact how the algorithm behaves. Options that alter the algorithm’s behavior, such as tolerance for error or the number of iterations. For as many parameters as the data has, time required to process the data training and processing time is frequently proportional. The greater the number of parameters the model’s dimensions, the more time it takes to process and train. However, an algorithm with numerous parameters means the method is adaptable. Machine learning addresses measurable variables. Having more features might slow down certain algorithms, therefore this causes them to take a lengthy time to train. So long as the issue has a large feature set, one should choose an algorithm such as SVM, which is best suited to those with numerous features.
References
Garg, A. (2020). Comparing Machine Learning Algorithms and Feature Selection Techniques to Predict Undesired Behavior in Business Processesand Study of Auto ML Frameworks. https://www.diva-portal.org/smash/record.jsf?pid=diva2%3A1498973&dswid=-4298
Lee, I., & Shin, Y. J. (2020). Machine learning for enterprises: Applications, algorithm selection, and challenges. Business Horizons, 63(2), 157–170. https://doi.org/10.1016/j.bushor.2019.10.005
Mahfouz, A. M., Venugopal, D., & Shiva, S. G. (2020). Comparative Analysis of ML Classifiers for Network Intrusion Detection (pp. 193–207). https://doi.org/10.1007/978-981-32-9343-4_16
Richter, C., Hüllermeier, E., Jakobs, M.-C., & Wehrheim, H. (2020). Algorithm selection for software validation based on graph kernels. Automated Software Engineering, 27(1–2), 153–186. https://doi.org/10.1007/s10515-020-00270-x
Vabalas, A., Gowen, E., Poliakoff, E., & Casson, A. J. (2019). Machine learning algorithm validation with a limited sample size. PLOS ONE, 14(11), e0224365. https://doi.org/10.1371/journal.pone.0224365

